Your cart is currently empty!

We just launched our courses -> Start learning today ✨


Overwhelmed by mountains of text data? In the world of digital marketing, especially in organic search and SEO, we are often faced with an overwhelming amount of information. Imagine implementing a classification Machine Learning algorithm, that can automatically classify documents (or other texts) in seconds!
With Google’s Natural Language API and Google Sheets, you can classify content in over 1,300+ categories in seconds. In the following guide, I will show you how, even without any coding experience, you can unlock the power of the text classification module of this API.
Text classification in machine learning deals with sorting text into predefined categories, or classes. The aim of the task is to automatically learn patterns in labeled examples (like emails marked spam or not spam) and then categorize new unseen text based on those patterns.
It is a supervised machine learning project, meaning that the model’s task is to predict the correct label of a given input data, following the training of the model. During training, the models is provided with a dataset pre-labeled examples, which enables it to become able to then classify new, unseen text into the categories.
The underlying technology (or algorithm used) is often either traditional model like Naive Bayes, Decision trees, or Support Vector Machines, or a deep learning neural network. Often word embeddings are also used to uncover semantic relationships of the words.
Text classification models help organize information, filter content, and gain insights from large amounts of text data.
Imagine a vast library filled with knowledge about language structure, grammar structure, sentiment, and real world entities. That’s essentially what the Natural Language API draws from. It’s trained on massive amounts of text data, allowing it to:
Google Cloud’s Natural Language API’s Content Classification module analyses a document and returns a content category that applies to the text found in the document. To classify the content in a document, call the classifyText method.
A complete list of content categories returned for the classifyText method are found in Google Cloud’s documentation files, depending on the model’s version: Version 1 content categories and Version 2 content categories.
The model essentially requires you to provide a text for it to analyze, and classify into one of the categories on its list. For each classification the model provides, there is an associated confidence score, which reflects how confident the model is that the text aligns to the category indicated.
Check out the additional resources by Google Cloud to practice working with this API, and the text classification module specifically:
Having selected your Google Cloud project, navigate to the APIs and Services menu > Credentials.
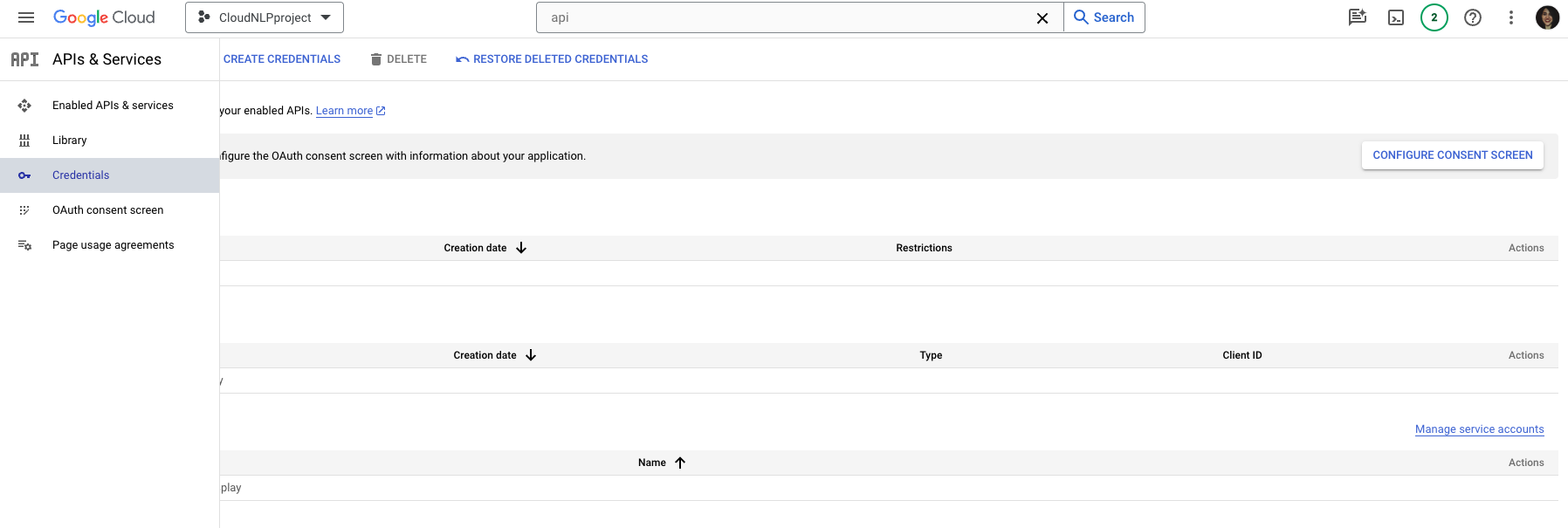
Then, click on the Create Credentials button from the navigation next to the page title, then select API Key from the drop-down menu.
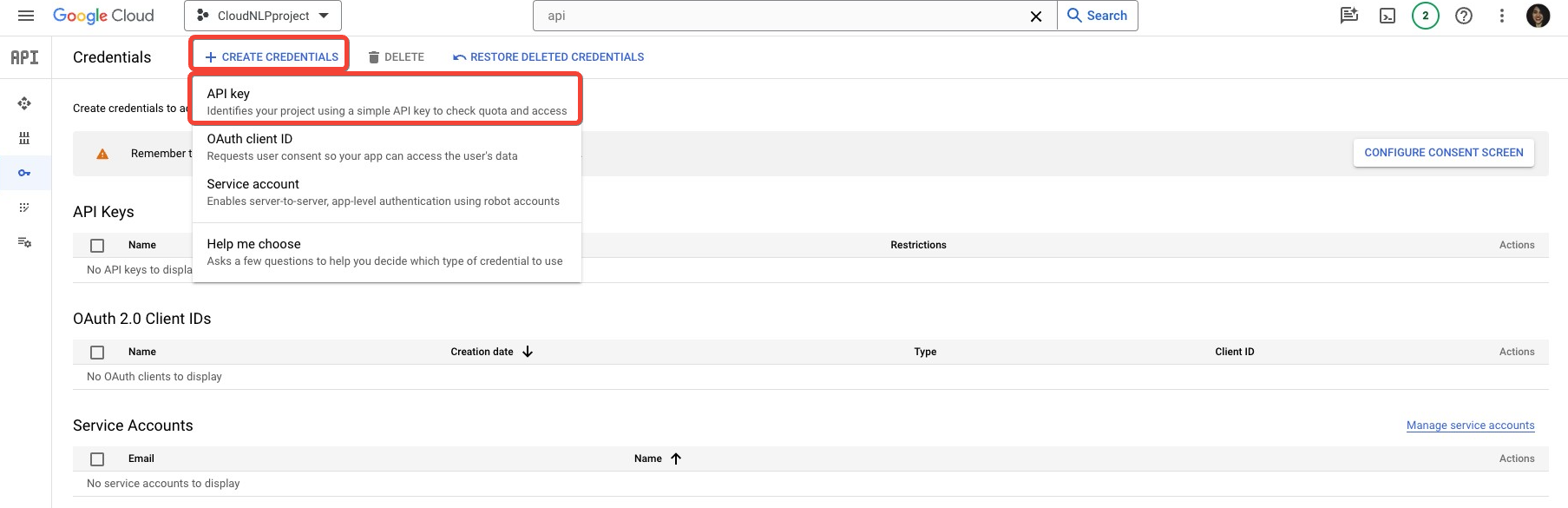
This is the easiest to use, but least secure method of authentication – you might consider alternatives for more complex projects.
Once you click on the Create API key button, there will be a pop-up menu that will indicate that the API key is being created, after which it will appear on the screen for you to copy.
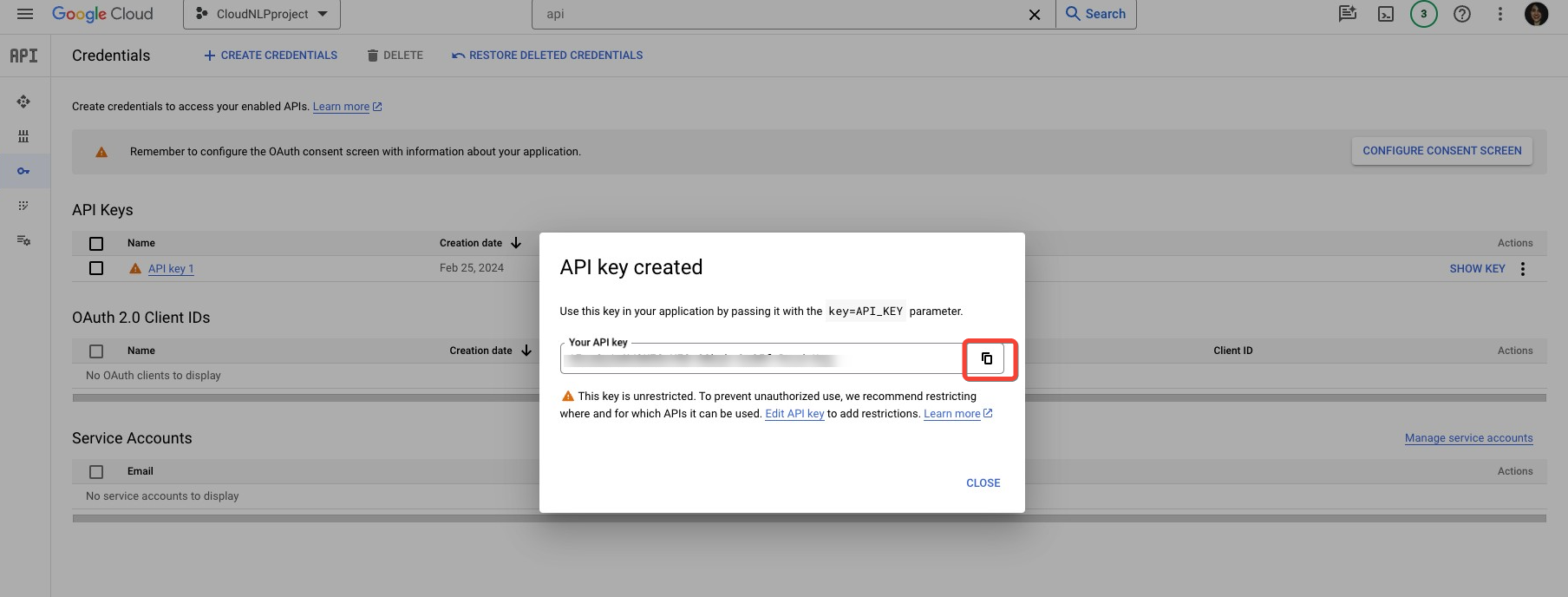
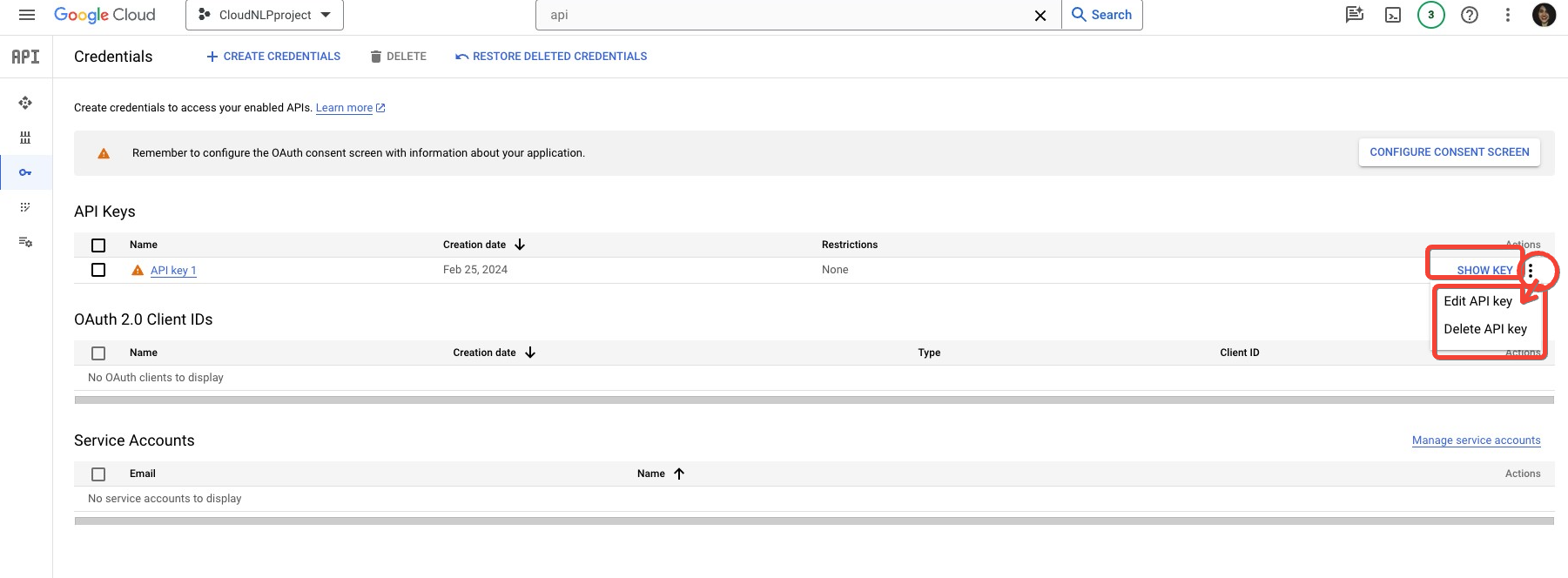
You can always navigate back to this section of your project, and reveal the API key at a later stage, using the Show Key button. If you ever need to edit or delete the API key, you can do so from the drop-down menu.
The next step is to decide on and organise the content you want to classify into Google Sheets.
For a no-code content scraping approach, I recommend using Screaming Frog’s custom extraction function. The approach works in three simple steps:
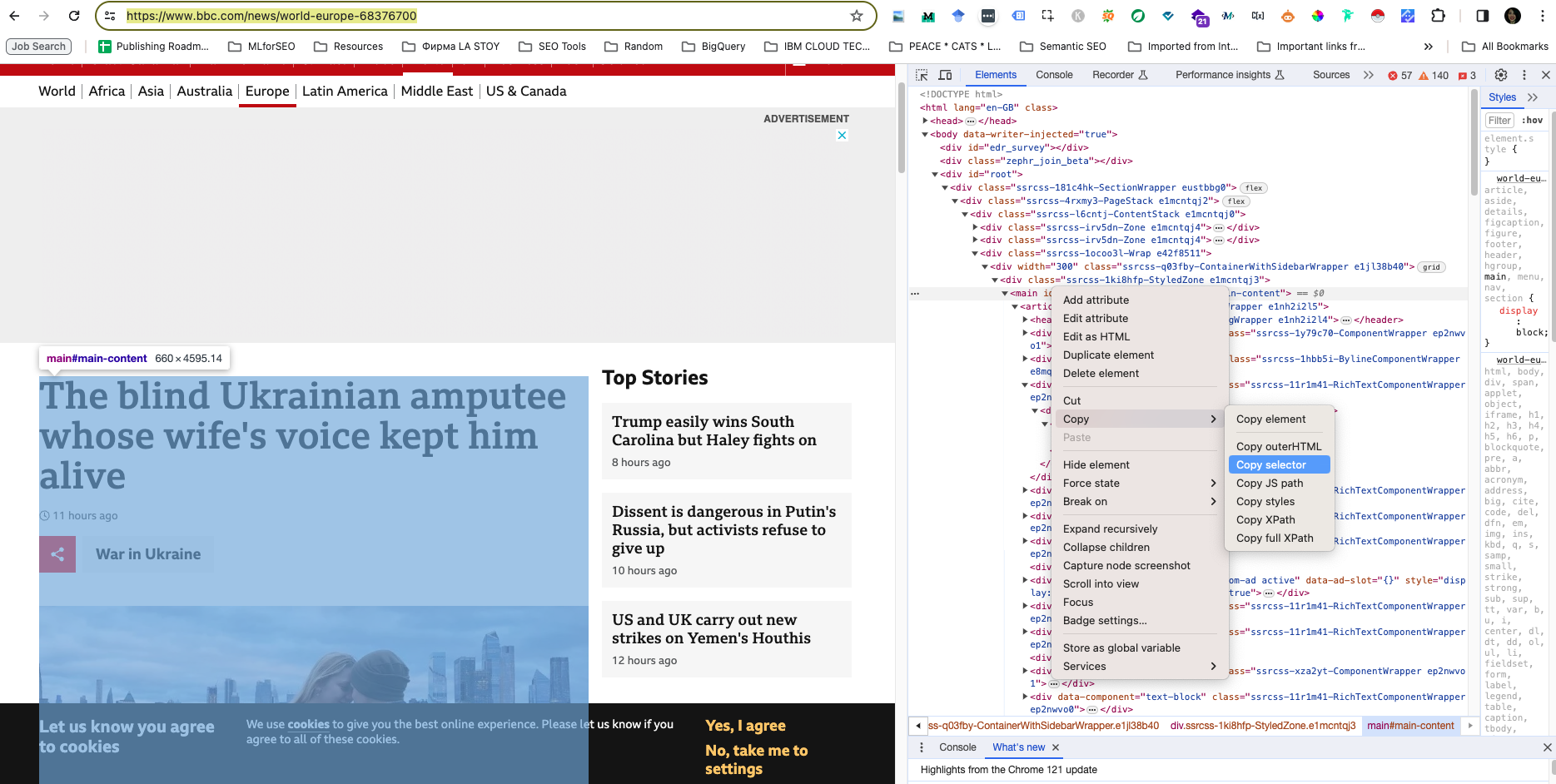
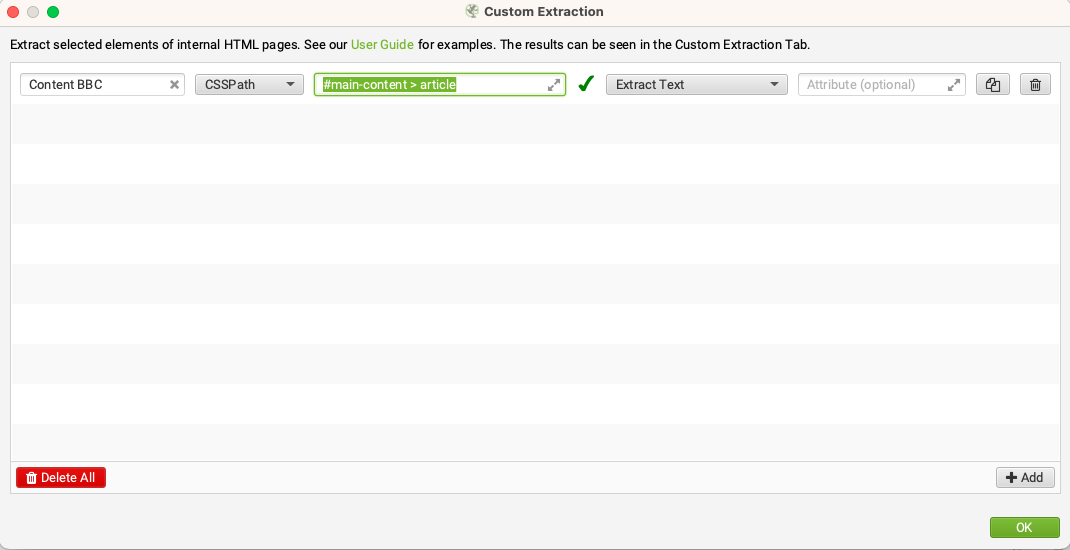
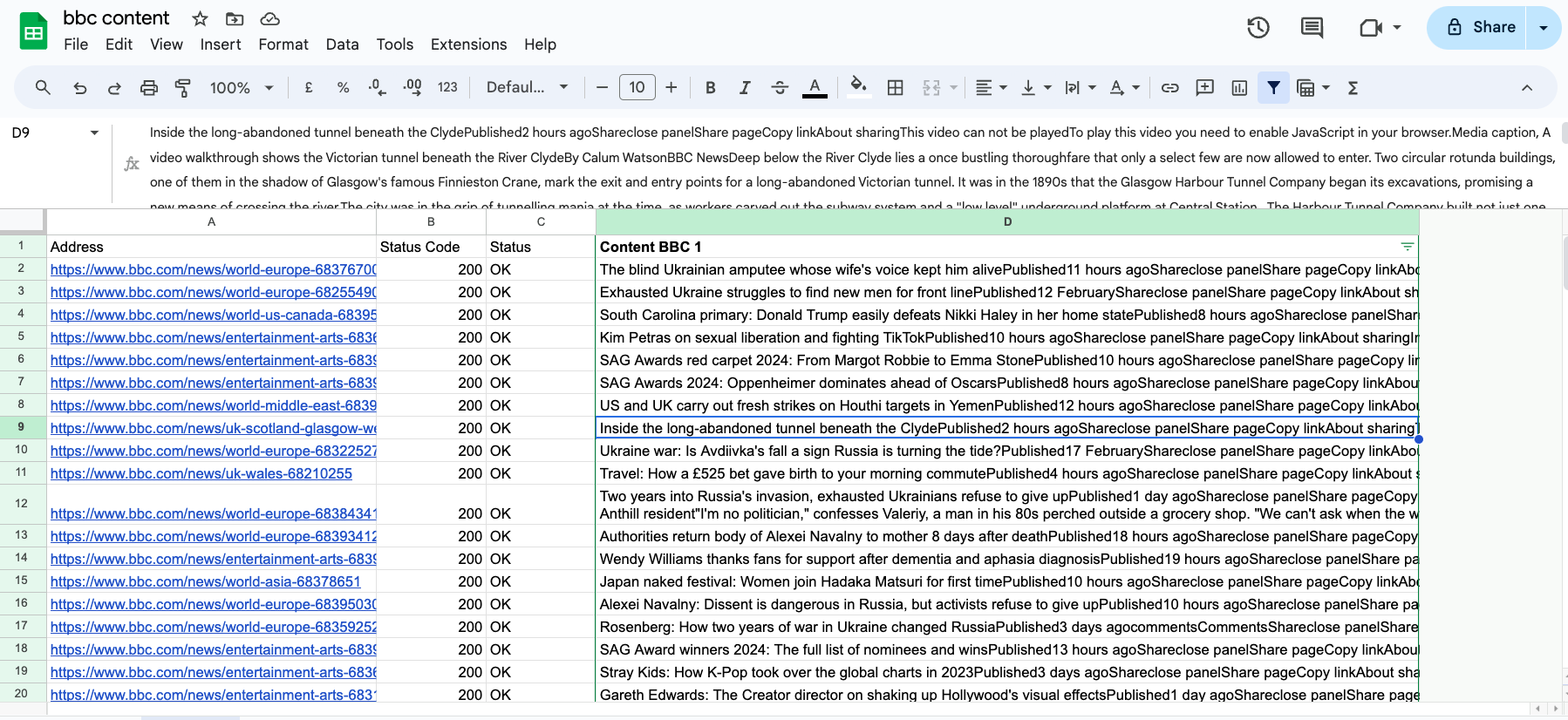
With this approach, you can quickly get a dataset of scraped content from web pages, or the HTML, depending on the extraction method you select.
You can also scrape content via alternative methods, using Python or third-party tools.
Once, you have your content extracted, you can move on to the next step.

Efficiently classify text in Google Sheets using our template for the Google Cloud Natural Language API text classification module, using Apps Script. Quick, beginner-friendly setup to get an accurate analysis for streamlined text processing and classification.
To prepare the data for analysis, we need to do two things – organize the content for analysis, and paste the API key in the script.
In Google Sheets, open the Extensions menu, and click on Apps Script.
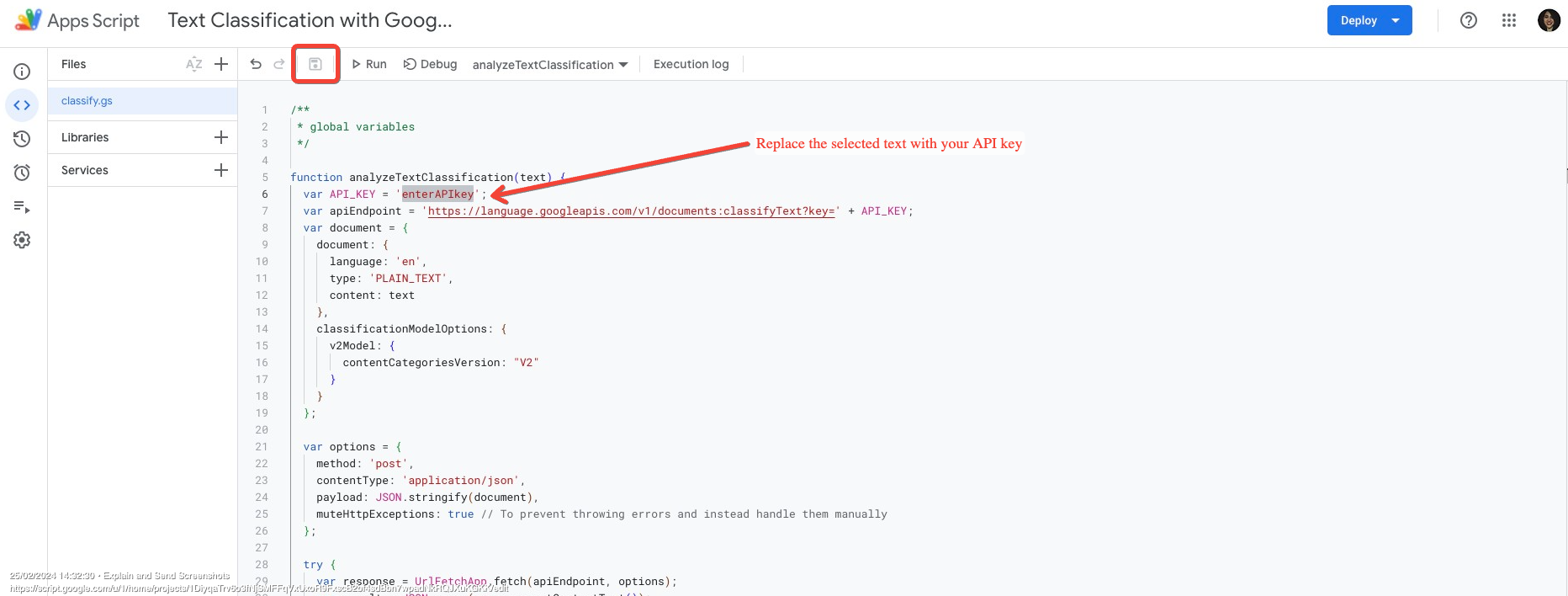
Open the classify.gs script attached, and select the text that says enterAPIkey. Replace it with your Google Cloud API project key. Then click on the disk icon to Save, and return to the Google Sheet file.
Paste your content for analysis in the Working Sheet, keeping the URL and content.
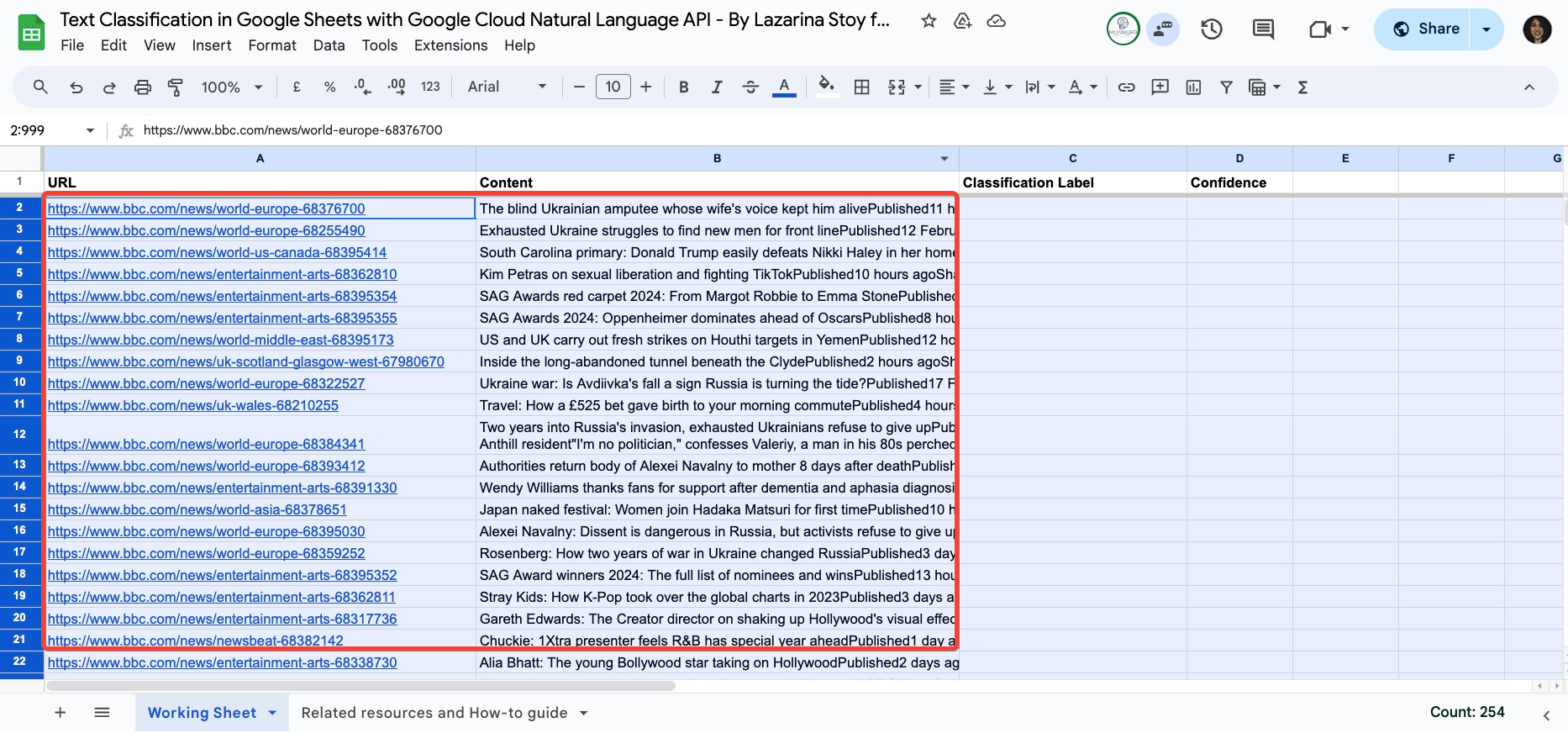
You can add any columns that you want to this file or perform any data cleaning or organisation operations you wish.
Make sure to the columns Classification Label and Confidence, where we will be pasting the results from the analysis.
To run the analysis, enter in the Classification Label column the formula below, replacing “text” with the cell, where the content you want to classify is.
=analyzeTextClassification(text)
Press enter, and drag and drop for the remaining rows.
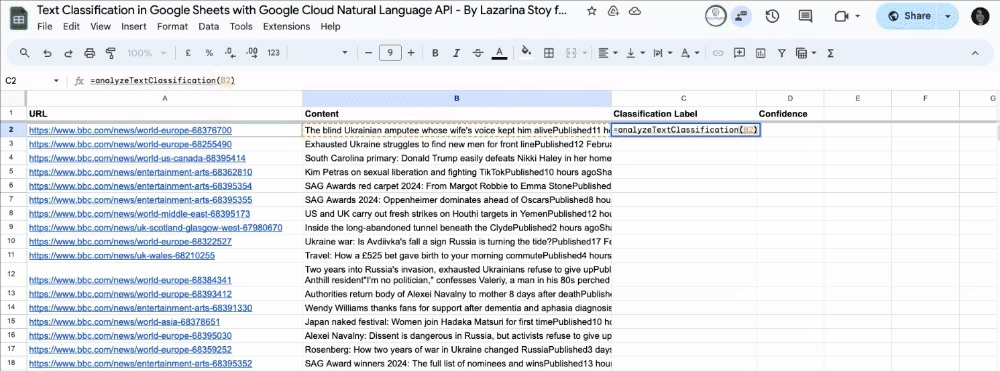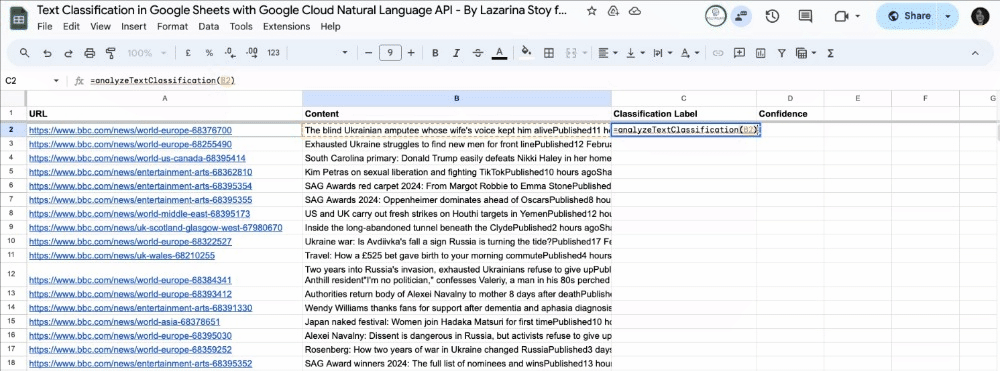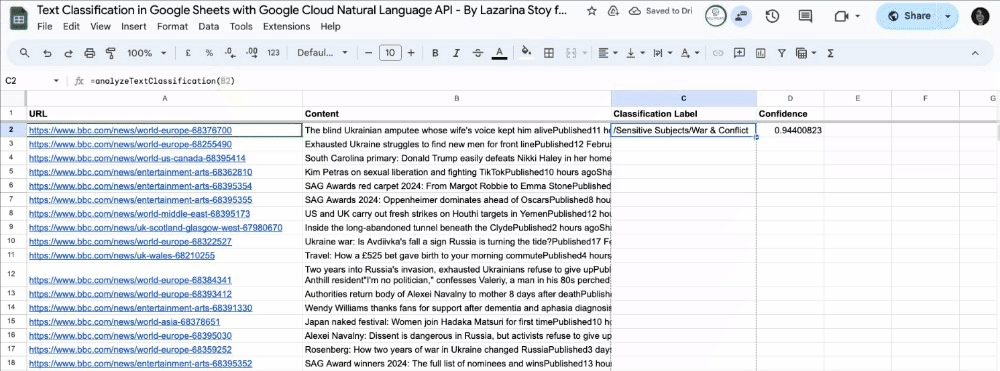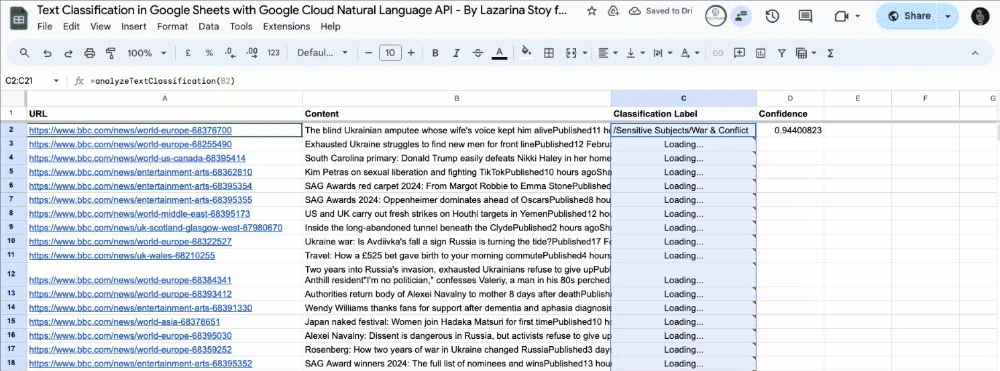
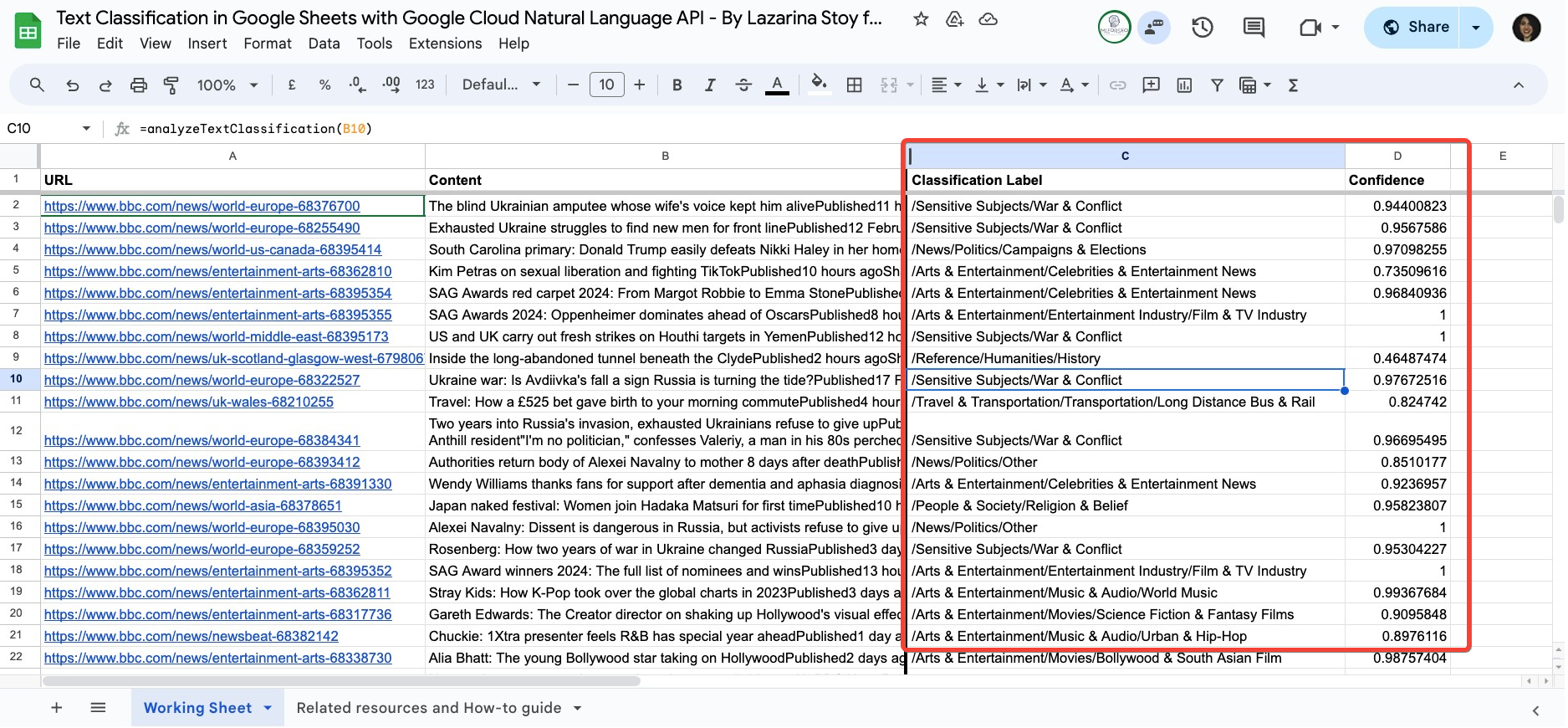
You can now review the output of how Google Cloud Natural Language API has classified your content, including the classification label and confidence score.

Although this step is optional, it is highly recommended that you visualize this data. For this purpose, I’ve created a handy Text Classification Looker Studio Dashboard Template, which allows you to:


This Looker Studio dashboard is based on data from text classification with Google’s Natural Language API tutorial. It offers a detailed and organized view of content classification labels across multiple levels, from primary to tertiary. It provides quick summaries, deep insights into label structures, and advanced filtering options, including Regex, for page URLs and content. Users can also exclude labels with low confidence scores, ensuring focus on the most accurate classifications.
Here are just some of the benefits of using the text classification module of Google’s Natural Language API in Google Sheets
Getting the data is one thing, learning how to analyse it and use it as part of Organic Search strategy is another. See the follow-up resources to learn how to harness this data to improve your strategy:
As mentioned at the start, the Natural Language API has several additional capabilities that include entity extraction, entity sentiment analysis, document sentiment analysis, and syntax analysis. Explore other step-by-step guides on this topic by visiting the resources, linked below:



Lazarina Stoy.







Beginner BERTopic FuzzyWuzzy Google Autocomplete API Google Cloud Natural Language API Google Colab (Python) Google Sheets (Apps Script) Intermediate KeyBERT kMeans OpenAI API sBERT Whisper API
Share this post on social media:
Leave a Reply