Keyword extraction is primarily used in Natural Language Processing (NLP) to identify the most relevant or important words or phrases (keywords) from a document or a set of documents.
In digital marketing, and particular in SEO tasks like keyword research or content auditing, this technique can be really useful for reducing noise from the keyword, title, paragraph or otherwise to only take the one (or few) words that most robustly, semantically represent the text.
In this guide, I’ll show you how to work with KeyBERT, and how to use it for keyword clustering in the process of keyword research.
About the model: KeyBERT
KeyBERT is a keyword extraction technique that uses BERT (Bidirectional Encoder Representations from Transformers) to generate relevant keywords from a given text. Unlike traditional keyword extraction methods that rely on statistical or linguistic approaches, KeyBERT leverages the powerful contextual embeddings of BERT to identify words or phrases that are most relevant to the content.
How it works
How KeyBERT works is, in short, it tokenizes the terms, extracts embeddings, and then it gives you the most important word. Here’s a quick breakdown of the process:
- Text Input: You provide a block of text (a document, sentence, or paragraph).
- Tokenization: Count Vectorizer and Scikit-learn are used to tokenize the document into candidate keywords
- Embedding Generation: Using BERT, KeyBERT converts the input text into contextual embeddings (numerical representations of words or phrases based on their meaning in context). Note that any language model can be used for this step, including: flair, gensim, spacy, or use.
- Keyword Extraction: KeyBERT computes the cosine similarity between the embedding of the full document and the embeddings of individual words or n-grams (short sequences of words).
- Relevance Scoring: Based on the similarity scores, KeyBERT ranks the keywords that best represent the input text.

In simple terms, from every sentence, from every keyword, you have one word that is the most vital one. That’s what KeyBERT tries to identify.

Additional Resources
I highly recommend learning directly from the person, who created KeyBERT, Maarten Grootendorst. Here are some great resources to get you started with KeyBERT (besides this tutorial, of course):
- Maarten’s video tutorial on working with KeyBERT
- Written tutorial on working with KeyBERT
- KeyBERT Documentation and GitHub Repo
How to work with KeyBERT in Google Colab (Python)
In the following section, we’ll go through how to work with KeyBERT with Python, using a demo Google Colab Notebook.
Prerequisites
There really isn’t much you need to get started working with this API. But the basics apply:
- Google Account: Ensure you have a Google account for accessing Google Colab.
- Google Colab: Get familiar with Google Colab as it will be the platform for executing Python code.
- Basic Python Knowledge: Have a fundamental understanding of Python programming to follow the code snippets and their execution.
Install the ML model and select a transformer
First step is importing the model by doing a pypi installation. You can install mode models to configure the transformer and language backends you’d like to use.

You then import the model and create a shortcut for using it in functions.
from keybert import KeyBERT
kw_model = KeyBERT()KeyBERT generic API use cases for text analysis
Use KeyBERT for keyword extraction
Once you have installed, imported KeyBERT into your Python script and initialized the model, provide your input text, and KeyBERT will extract keywords based on their semantic relevance.
The model evaluates candidates against the original text using cosine similarity, ensuring that the extracted keywords capture the essential themes.
#Basic usage - keyword extraction
from keybert import KeyBERT
doc = """
Supervised learning is the machine learning task of learning a function that
maps an input to an output based on example input-output pairs. It infers a
function from labeled training data consisting of a set of training examples.
In supervised learning, each example is a pair consisting of an input object
(typically a vector) and a desired output value (also called the supervisory signal).
A supervised learning algorithm analyzes the training data and produces an inferred function,
which can be used for mapping new examples. An optimal scenario will allow for the
algorithm to correctly determine the class labels for unseen instances. This requires
the learning algorithm to generalize from the training data to unseen situations in a
'reasonable' way (see inductive bias).
"""
kw_model = KeyBERT()
keywords = kw_model.extract_keywords(doc)
print(keywords)
This approach not only provides relevant keywords but also offers flexibility in specifying keywords or allowing the model to generate them autonomously.
Use KeyBERT for #n-gram specified keyword extraction
N-gram specified keyword extraction using KeyBERT allows for the identification of keywords at both the unigram and bigram levels. This approach enhances the contextual understanding of the text by capturing single words (unigrams) and pairs of consecutive words (bigrams) as keywords.
To extract unigrams using KeyBERT, you can specify the extraction of individual keywords while setting the top_n parameter to control the number of keywords returned. Here’s how to implement unigram extraction:
#n-gram specified keyword extraction
kw_model.extract_keywords(doc, keyphrase_ngram_range=(1, 1), stop_words=None)
In unigram extraction, each individual word is treated as a separate keyword. This method is straightforward and allows for a quick analysis of the most semantically important terms within a document.
For bigram extraction, you can adjust the keyphrase_ngram_range parameter to (2, 2) in KeyBERT, allowing the model to focus on pairs of consecutive words. This helps capture meaningful phrases in the text. Here’s an example:
kw_model.extract_keywords(doc, keyphrase_ngram_range=(2, 2), top_n=10, stop_words=None)With KeyBERT for both unigram and bigram keyword extraction, you can enhance your analysis, capturing essential terms and phrases that contribute to a deeper understanding of the text. You can specify other lengths of the n-grams, as well and customise this implementation further.
Use KeyBERT to highlight the most important terms in a document, paragraph or content piece
To highlight the most important terms in a document, you can use KeyBERT’s extract_keywords function with the highlight=True parameter. This feature allows you to visually emphasize the relevant keywords directly within the text. Here’s a concise example:
#highlight keywords in the document
keywords = kw_model.extract_keywords(doc, highlight=True)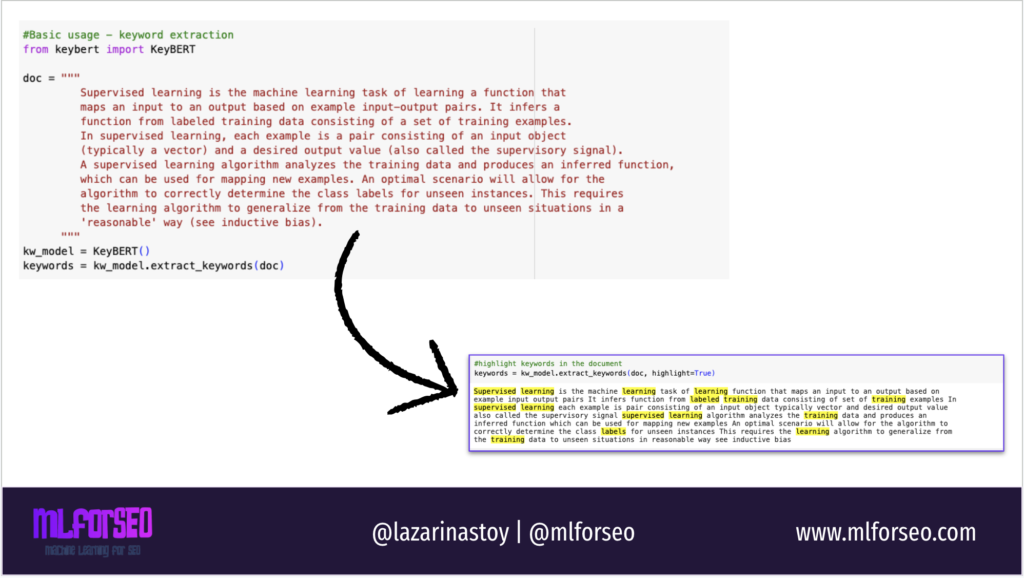
This makes it easier to identify key concepts and themes within the content at a glance, and help you identify if you’re stuffing keywords in your text. This can also be applied for the content of your competitors, but also for personal uses like email or social text analysis to improve readibility.
KeyBERT for SEO Keyword Clustering in csv/Excel- SEO Use case
In this notebook, we’ll use the KeyBERT library to automatically extract keyphrases from a list of keywords. The keyphrases are derived from the text data using pre-trained BERT models, making this approach highly accurate for identifying meaningful keywords.
Function explaination
Here are the steps we’ll execute:
- Upload your file
You can upload a CSV or Excel file that contains a column named Keywords. The notebook supports both file formats, so you can upload .csv, .xls, or .xlsx files directly.
2. Keyword Extraction
The KeyBERT model will analyze the Keywords column and extract
- Core (1-gram): The most relevant single-word keyword.
- Core (2-gram): The most relevant two-word phrase.
2. Get the results and download your csv file
After processing, two new columns will be added to the DataFrame:
- Core (1-gram): The top 1-word keyphrase.
- Core (2-gram): The top 2-word keyphrase.
The DataFrame, with the new columns, will be saved as a CSV file and automatically downloaded.
Functions used
- KeyBERT: A simple and powerful library that uses BERT embeddings to extract keyphrases that are most representative of the input text.
- File Upload: You will be prompted to upload a file containing your keywords. The file should contain a column named Keywords where the keyword or text data resides.
- Output: Once the keywords are processed, you will receive a CSV file with the original keywords and their corresponding main 1-gram and 2-gram keyphrases.
Code to use
Click on the image below to go to the Colab notebook with the code to use.

Alternatively, feel free to copy and modify this code as you see fit.
# Install the necessary libraries
#!pip install keybert
#!pip install transformers
!pip install openpyxl # For handling Excel files
import pandas as pd
from keybert import KeyBERT
from google.colab import files
from google.colab import drive
# Initialize the KeyBERT model
kw_model = KeyBERT()
# Function to load a dataframe from a file uploaded by the user
def load_dataframe():
# User uploads either a CSV or Excel file
print("Please upload a CSV or Excel file:")
uploaded = files.upload()
filename = list(uploaded.keys())[0] # Get the name of the uploaded file
# Check the file extension and load accordingly
if filename.endswith('.csv'):
df = pd.read_csv(filename)
elif filename.endswith(('.xls', '.xlsx')):
df = pd.read_excel(filename)
else:
print("Unsupported file type. Please upload a CSV or Excel file.")
return None
return df
# Function to apply KeyBERT on the 'Keywords' column
def apply_keybert(df):
if 'Keywords' not in df.columns:
print("Error: The dataframe must contain a column named 'Keywords'.")
return None
# Create new columns for unigrams and bigrams
def extract_ngram(text, ngram_range):
# Extract keywords with specified ngram range, handle the case where no keywords are found
keywords = kw_model.extract_keywords(text, keyphrase_ngram_range=ngram_range, stop_words='english')
return keywords[0][0] if keywords else "" # Return the keyword or an empty string if none found
# Apply to the 'Keywords' column
df['Core (1-gram)'] = df['Keywords'].apply(lambda x: extract_ngram(x, (1, 1)) if len(x) > 0 else "")
df['Core (2-gram)'] = df['Keywords'].apply(lambda x: extract_ngram(x, (2, 2)) if len(x) > 0 else "")
return df
# Main function to upload the file and apply the transformations
def main():
df = load_dataframe()
if df is not None:
# Apply KeyBERT to extract keywords
df_with_keybert = apply_keybert(df)
if df_with_keybert is not None:
# Show the modified dataframe
print(df_with_keybert.head())
# Save the modified dataframe to a new CSV
df_with_keybert.to_csv('keywords_with_keybert.csv', index=False)
print("File saved as 'keywords_with_keybert.csv'.")
files.download('keywords_with_keybert.csv')
# Call the main function
main()Results
After uploading your file, the notebook will automatically apply KeyBERT to extract keywords and download the processed file.
Provided that your input looks like the image on the left, your downloaded file will look like the image on the right, with two columns added: Core (1-gram) and Core (2-gram).

Visualise
You can then visualise this data, or use it for keyword or page tagging purposes.


Ideally, what you’d like to do with this data would be to incorporate the keyword labels into your keyword research or semantic keyword universe, so that your visualisations can reflect other metrics (not only count of keywords per cluster) like
- sum of search volume per cluster, helping you prioritize clusters that can drive the most traffic
- average keyword difficulty per cluster, , allowing you to strategize your SEO efforts based on competitiveness
- most important entities per cluster, which helps to understand the main topics and themes, which can guide content creation and optimization
- competitors per cluster, analyzing which competitors are targeting the same keywords allows you to evaluate the competitive landscape, identify gaps in your strategy, and refine your approach to outperform them.
- average cost-per-click (CPC) per cluster, helping to evaluate the advertising potential of keywords;
- trends over time per cluster, enabling you to identify seasonal shifts in keyword performance;
- social media mentions per cluster, which can highlight brand sentiment and visibility within social channels.
Key Takeaways on KeyBERT for keyword extraction and clustering
In this KeyBERT tutorial, we explored the powerful capabilities of KeyBERT for keyword extraction, text analysis, and keyword clustering. Here are the key takeaways:
- KeyBERT leverages BERT embeddings to identify the most relevant keywords from any given text, ensuring a contextual understanding that surpasses traditional frequency-based methods.
- By using KeyBERT, you can perform n-gram specified keyword extraction, allowing you to capture both unigrams and bigrams. This flexibility helps in analyzing single words and meaningful phrases, enriching your content strategy.
- KeyBERT’s
extract_keywordsfunction with thehighlight=Trueparameter enables users to visually emphasize important terms within their documents, enhancing readability and focus. - Incorporating keyword labels into your keyword research allows for a richer semantic keyword universe, facilitating deeper insights through various metrics.
- Utilizing metrics such as the sum of search volume, average keyword difficulty, most important entities, and competitors per cluster can lead to better-informed decision-making and strategic planning.
By analyzing keyword performance, competition, and contextual relevance, you can develop more effective content optimization strategies that align with user intent and market demands.
Overall, KeyBERT serves as a robust tool for keyword extraction and analysis, empowering marketers, content creators, and SEO professionals to enhance their strategies through data-driven insights.
Lazarina Stoy is a Digital Marketing Consultant with expertise in SEO, Machine Learning, and Data Science, and the founder of MLforSEO. Lazarina’s expertise lies in integrating marketing and technology to improve organic visibility strategies and implement process automation.
A University of Strathclyde alumna, her work spans across sectors like B2B, SaaS, and big tech, with notable projects for AWS, Extreme Networks, neo4j, Skyscanner, and other enterprises.
Lazarina champions marketing automation, by creating resources for SEO professionals and speaking at industry events globally on the significance of automation and machine learning in digital marketing. Her contributions to the field are recognized in publications like Search Engine Land, Wix, and Moz, to name a few.
As a mentor on GrowthMentor and a guest lecturer at the University of Strathclyde, Lazarina dedicates her efforts to education and empowerment within the industry.
- Lazarina Stoy.

- Lazarina Stoy.

- Lazarina Stoy.
- Lazarina Stoy.