Your cart is currently empty!
We just launched our courses -> Start learning today ✨

Different ways to Map Keywords to topics – with Supervised and Unsupervised ML approaches

Mapping keywords to topics can be a useful step in organising your keyword research process and your semantic keyword universe. It allows you to understand how terms relate to one another, cluster keywords together, and better visualise the importance from a search engine visilibity standpoint of these topic clusters comprised of various related keywords. When paired with keyword entity analysis or search intent classification, this exercise can completely change the way you look at keywords.
By leveraging both supervised and unsupervised machine learning approaches, we can move beyond simple term matching and into semantic connections, contextual groupings, and deeper thematic insights.
In this guide, I’ll explore four different methods that can help you map keywords to topics effectively, each varying in complexity and effectiveness for the task, yet each with their own merits and applications:
- String fuzzy matching, a lightweight method for approximate matches between keywords and topics.
- sBERT (Sentence-BERT) for topic clustering with semantic similarity,
- BERTopic, a powerful unsupervised approach for dynamic topic modeling, and
- K-Means Clustering, a classic unsupervised ML method for grouping keywords based on vectorized features.
Each of these methods offers unique strengths and is suited to different stages of keyword analysis. Whether you’re building a complex topic model for a massive dataset or fine-tuning results with specific match criteria, these techniques can help you create a structured and actionable keyword universe.
And don’t worry—this guide will walk you through each step, and I’ll provide all the code you need in a beginner-friendly Google Colab notebook.
✨ If you’re interested about taking your keyword research to the next level, consider my course on Semantic ML-enabled Keyword Research, out now on the MLforSEO Academy.
UNDERSTAND QUERY SEMANTICS
Semantic ML-Enabled Keyword Research Course
Dive into query semantics and machine learning to improve your keyword research methods. This course will teach you how to find untapped keywords, understand user intent at scale, and boost your content’s visibility using cutting-edge ML and automation techniques. Includes a ton of information on patents and practical exercises!

About keyword to topic mapping with machine learning approaches
Mapping keywords can enable you to group related terms and better understand how users think and search. Organic marketers, like myself, use this technique to create connections between website’s own ranked keywords, competitor keywords, or query paths and Google Autosuggested terms and topic labels, allowing for better understanding of the opportunities each keyword-topic cluster presents for the organisation.
How it works – Machine Learning Models to Map Keywords to Topics
In this guide, we’ll go through four different machine learning approaches on mapping keywords to topics. In my practice and work in SEO projects, including but not limited to keyword research, I’ve found a place for each of these methods into my process, though some are undoubtedly a better (more accurate and robust), while others are better suited for quick-and-dirty analysis or database organisation work.
Let me explain how each of these work, then I’ll summarise the main benefits and limitations and show you some use cases for keyword research specifically, for each of these approaches.
String Fuzzy Matching
String fuzzy matching is a lightweight, heuristic approach for finding approximate matches between keywords and predefined topic categories. Unlike embedding-based methods, it operates on textual similarity, using algorithms like Levenshtein distance to measure how closely two strings resemble each other. This means it does not consider semantics of keywords and terms, making it undoubtedly the most rudimentary of approaches, discussed in this guide.
This method is ideal for smaller datasets or scenarios where computational resources are limited. While less sophisticated than embedding-based models, it offers a quick and effective solution for tasks that don’t require semantic depth.
sBERT (Sentence-BERT)
sBERT is a supervised machine learning model designed to capture semantic meaning from text. It builds on BERT (Bidirectional Encoder Representations from Transformers) by allowing efficient comparison of sentence or phrase embeddings. In the context of keyword mapping, sBERT generates dense vector representations for keywords, enabling precise clustering based on semantic similarity. This makes it particularly powerful for grouping terms that are contextually related but may not share exact lexical overlap. Its ability to preserve semantic nuance is invaluable when working with datasets that require fine-grained topic categorization.
For those needing a refresher, supervised in this context means that you have a list of keywords and you also have a list of topics you’d like to assign these terms to. The model assigns a topic to each term and gives a prediction accuracy score, based on the training. This model is very good and custom-trained for short-form text (sentence-length), making it ideal for keyword or title analysis.
K-Means Clustering
K-Means Clustering is a classic unsupervised learning technique that partitions data into a specified number of clusters based on their features. For keyword mapping, this involves transforming keywords into numerical vectors—often through word embeddings—and then grouping them by minimizing the variance within clusters.
K-Means excels at identifying clear groupings in moderately large datasets, especially when the desired number of clusters is known. It provides a straightforward, computationally efficient approach for creating keyword groups aligned with distinct topics.
Practically-speaking, K-means clustering only partitions the dataset you provide – it does not assign labels to clusters, nor can it map a label you provide to each term. Though, as you can see from the provided code, we can certainly adjust our script to visually highlight some sample terms from each cluster to ease the data analysis work.
BERTopic
BERTopic is another unsupervised machine learning approach that applies topic modeling frameworks, combining embeddings and clustering to produce interpretable topic representations. Using transformer-based embeddings, BERTopic uncovers latent themes in large keyword datasets and assigns terms to dynamic, evolving clusters.
What sets it apart is its ability to generate human-readable topic labels based on representative keywords, making it highly suitable for content strategy and SEO applications. BERTopic is particularly effective when working with large, unstructured keyword datasets where the number of topics is unknown or may vary. It’s also great, as it allows the user to configure each step of the topic modelling algorithm like a lego, fine-tuning the algorithm and it’s output based on the dataset characteristics.
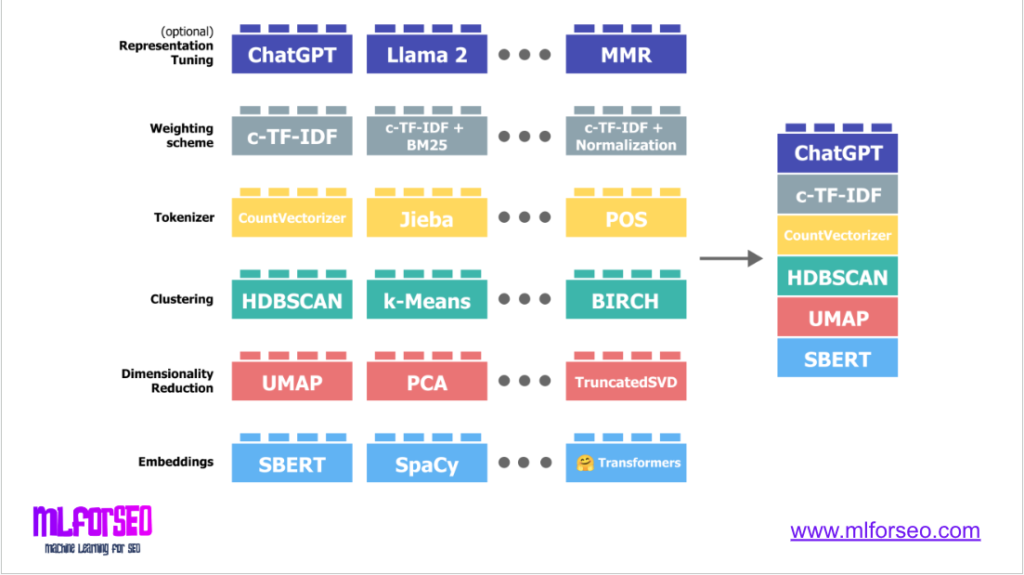
With BERTopic, at a minimum, you’d just need your keyword list, and optionally (but not necessarily) the number of topics, and the output would include a list of topics for the entire dataset, as well as topic labels based on prominent terms for each topic, and the individual keyword-to-topic mapping.
| Method | Approach | Strengths | Best Use Cases |
|---|---|---|---|
| String Fuzzy Matching | Supervised, heuristic, string-based | Quick, lightweight, easy to implement | Small datasets, approximate matching tasks |
| sBERT (Sentence-BERT) | Supervised, embedding-based | High semantic precision, handles nuanced relationships | Detailed classification, contextual keyword analysis |
| K-Means Clustering | Unsupervised, vector-based | Simple, scalable, computationally efficient | Moderately large datasets with predefined cluster counts |
| BERTopic | Unsupervised, topic modeling | Generates interpretable topics, dynamic clustering | Large unstructured datasets, exploratory keyword analysis |
How to do keyword to topic mapping in Python
In the following sections, I’ll show you how to test the different machine learning approaches for keyword to topic mapping, and discuss how the expected model outputs can be useful in the context of keyword research or other SEO projects.
Make a copy of the Keyword to Topic mapping – Supervised approaches (you have topic labels) with sBERT and Fuzzy matching or unsupervised (you don’t have labels) with BERTopic and k-means — by Lazarina Stoy for MLforSEO, as that’s what we’ll be working with for the rest of this guide.
Prerequisites
There really isn’t much you need to get started working with these APIs. But the basics apply:
- Google Account: Ensure you have a Google account for accessing Google Colab.
- Google Colab: Get familiar with Google Colab as it will be the platform for executing Python code.
- Basic Python Knowledge: Have a fundamental understanding of Python programming to follow the code snippets and their execution.
Keyword to topic mapping with fuzzy matching
This approach relies on algorithms like Levenshtein distance, which evaluates the minimum number of edits (inserts, deletes, or substitutions) needed to transform one string into another. By scoring the similarity between keywords, fuzzy matching allows us to align keywords to their closest topic with high accuracy.
How the Code Works
- Uploading Data: The script starts by requiring two CSV files:
seed.csv: A file containing seed keywords that represent the topics or categories you want to map keywords to.match.csv: A file containing the keywords you want to align with the seed keywords.
- Fuzzy Matching: The core function iterates through the match keywords and compares each one against the seed keywords using a similarity score. The score is calculated using
fuzz.partial_ratio, which handles substring matching by comparing only the most relevant parts of the strings. For each keyword in the match list, the algorithm identifies:- The best matching seed keyword.
- The similarity score between the two keywords.
- Generating Results: The output is a table (or dataframe) that contains:
- The original keyword from the match list.
- The best matching seed keyword.
- The similarity score indicating the strength of the match.
- Saving the Results: The script saves the results into a new CSV file (
fuzzy_matching_result.csv) for easy sharing or integration into further workflows.
Input Requirements and Results
- Inputs:
seed.csvshould contain a column namedKeywordswith the seed keywords.match.csvshould contain a column namedKeywordswith the keywords to be mapped.
- Output:
The output is a CSV file where each match keyword is paired with its best seed keyword and a match score, providing actionable insights into the alignment between keywords and topics.

This lightweight method is perfect for scenarios where computational simplicity and quick results are priorities. It can handle datasets of moderate size and offers an intuitive way to map keywords to topics without requiring advanced machine learning models.
Click here to view the entire function / Python Code
# Install required libraries
!pip install fuzzywuzzy
!pip install pandas
!pip install python-Levenshtein
# Import necessary libraries
from fuzzywuzzy import fuzz
import pandas as pd
from google.colab import files
from io import BytesIO
# Upload the 'seed.csv' (seed keywords) and 'match.csv' (keywords to be matched)
uploaded = files.upload() # Upload seed.csv and match.csv files
# Read the uploaded seed keywords CSV file (seed.csv)
seed_file = next(iter(uploaded.values()))
seed_keywords_df = pd.read_csv(BytesIO(seed_file))
print("Seed Keywords CSV:")
print(seed_keywords_df.head()) # Show first few rows of seed keywords
# Extract the seed keywords into a list
seed_keywords = seed_keywords_df['Keywords'].tolist()
# Upload the match keywords CSV file (match.csv)
uploaded_files = files.upload()
match_file = next(iter(uploaded_files.values()))
match_keywords_df = pd.read_csv(BytesIO(match_file))
print("Match Keywords CSV:")
print(match_keywords_df.head()) # Show first few rows of match keywords
# Extract the match keywords into a list
match_keywords = match_keywords_df['Keywords'].tolist()
# Function to find the best fuzzy match for each keyword
def find_best_match(seed_keyword, keyword_list):
best_match = None
highest_score = 0
for keyword in keyword_list:
score = fuzz.partial_ratio(seed_keyword.lower(), keyword.lower()) # Fuzzy matching score
if score > highest_score:
highest_score = score
best_match = keyword
return best_match, highest_score
# For each match keyword, find the best match from seed keywords
matches = []
for match in match_keywords:
matched_seed_keyword, score = find_best_match(match, seed_keywords) # Find best match from seed
matches.append((match, matched_seed_keyword, score))
# Create a DataFrame with the results
result_df = pd.DataFrame(matches, columns=['Match Keyword', 'Best Seed Keyword', 'Match Score'])
# Display the resulting matches
print(result_df.head()) # Show first few rows of results
# Save the result to a new CSV file
result_df.to_csv('fuzzy_matching_result.csv', index=False)
# Provide the file for download
files.download('fuzzy_matching_result.csv')
Keyword to topic mapping with sBERT
sBERT (Sentence-BERT) is a powerful model for generating sentence embeddings, which are dense vector representations of text that capture semantic meaning. In the context of keyword-to-topic mapping, sBERT enables us to measure the similarity between keywords and topics, making it an excellent tool for creating structured, meaningful relationships between the two.
How the Process Works
This implementation of sBERT for keyword-to-topic mapping consists of five main steps:
- Upload and Prepare Data: Two CSV files are required:
keywords.csv: Contains the list of keywords you want to map.topics.csv: Contains the potential topics you want to assign to keywords.
- Generate Embeddings: Using the
all-MiniLM-L6-v2sBERT model, embeddings are generated for both keywords and topics. These embeddings capture the semantic relationships between the terms, representing them in a high-dimensional vector space. - Calculate Similarities: Cosine similarity is computed between each keyword and all topics, resulting in a similarity matrix that quantifies how closely related each keyword is to every topic.
- Assign Topics to Keywords: For each keyword, the script identifies the topic with the highest similarity score and assigns it as the closest match. This ensures that keywords are mapped to their most relevant topic.
- Save Results: The results are saved in a new CSV file,
keyword_topic_mapping.csv, which includes each keyword, its assigned topic, and the similarity score.
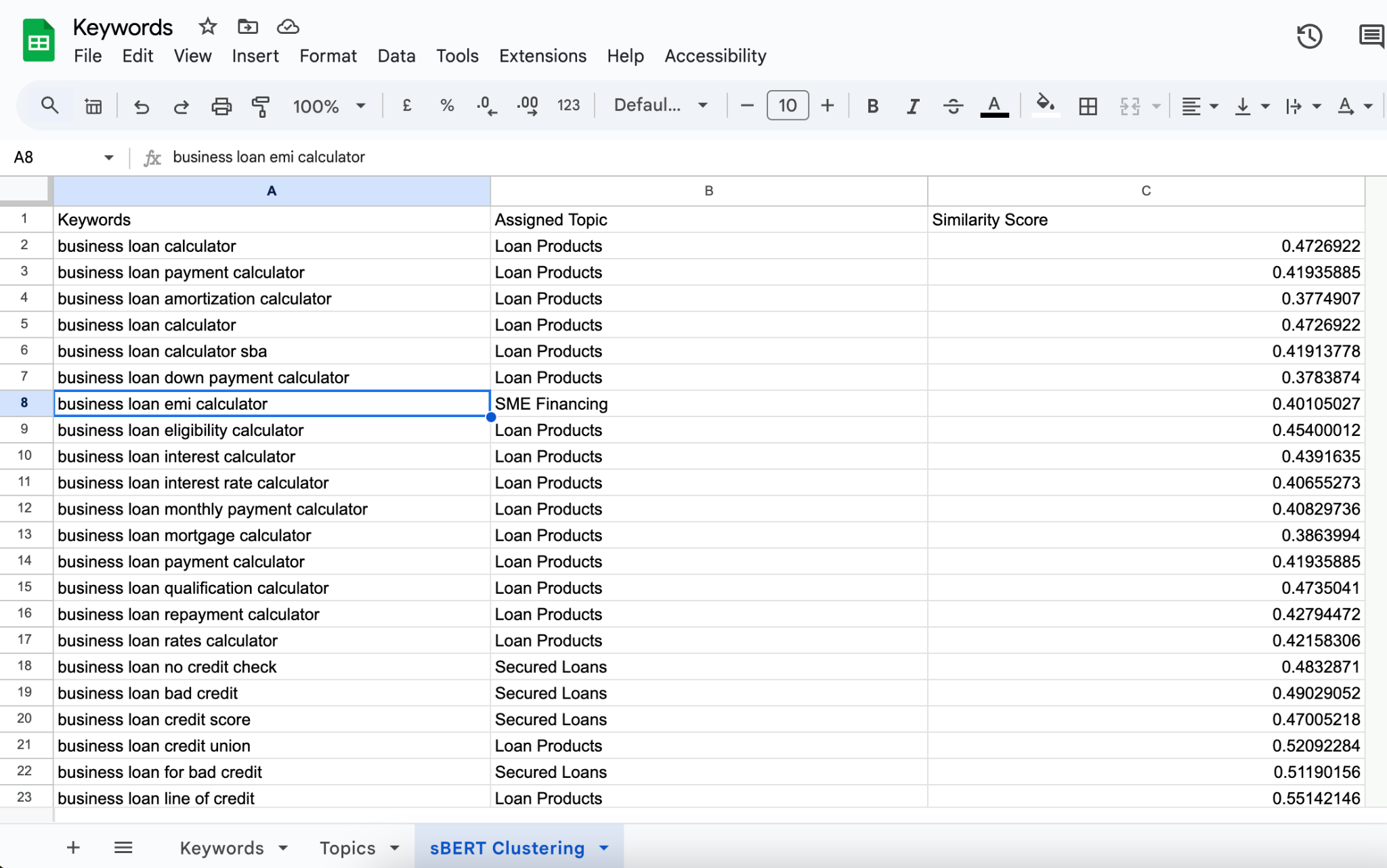
One key benefit of this approach is its precision and scalable mapping, especially useful for large datasets of keywords. By leveraging semantic embeddings, sBERT enables mapping even when keywords and topics don’t share direct lexical overlap. The result is a robust, data-driven mapping that enhances your ability to organize content or perform keyword analysis.
Click here to view a sample of the Python code
from sentence_transformers import SentenceTransformer
from sklearn.metrics.pairwise import cosine_similarity
# Load the model
model = SentenceTransformer('all-MiniLM-L6-v2') # Lightweight and free-to-use sBERT model
# Step 2: Embed keywords and topics
keywords = keywords_df['Keywords'].tolist()
topics = topics_df['Topics'].tolist()
# Generate embeddings for both keywords and topics
keyword_embeddings = model.encode(keywords)
topic_embeddings = model.encode(topics)
# Step 3: Calculate similarity
# Compute cosine similarity between each keyword and all topics
similarity_matrix = cosine_similarity(keyword_embeddings, topic_embeddings)
# Step 4: Assign keywords to closest topic
# Get the index of the most similar topic for each keyword
closest_topics_indices = similarity_matrix.argmax(axis=1)
# Map the closest topic to each keyword
keywords_df['Assigned Topic'] = [topics[idx] for idx in closest_topics_indices]
# Step 5: (Optional) Add similarity scores for analysis
keywords_df['Similarity Score'] = similarity_matrix.max(axis=1)
# Save the results to a new CSV
output_file = 'keyword_topic_mapping.csv'
keywords_df.to_csv(output_file, index=False)
print(f"Keyword-to-Topic mapping saved to {output_file}")
# Download the output file
files.download(output_file)Keyword to topic mapping with k-means clustering
K-Means clustering is one of the most versatile unsupervised machine learning techniques. It excels at grouping entities into clusters based on their semantic relevance, making it an ideal tool for keyword and entity analysis. By applying this method, we can identify patterns in textual data, organize entities into cohesive groups, and visualize these relationships for deeper insights.
In this implementation, we enhance K-Means clustering with TF-IDF vectorization and dimensionality reduction using PCA, enabling efficient grouping and a clear, visual understanding of the results.
How the Process Works
- Data Preparation:
The process begins with a CSV file containing anEntitycolumn. Each entity represents a keyword, term, or phrase to be analyzed. These entities are vectorized using the TF-IDF (Term Frequency-Inverse Document Frequency) method, which transforms textual data into numerical features while preserving semantic relationships. - Clustering with K-Means:
Using the TF-IDF features, the entities are clustered into a specified number of groups (num_clusters) using the K-Means algorithm. Each entity is assigned to the cluster it is most similar to, creating distinct groupings of semantically related terms. - Visualization with PCA:
To make the clusters interpretable, the high-dimensional TF-IDF data is reduced to two dimensions using Principal Component Analysis (PCA). A scatter plot visualizes the clusters, with each point representing an entity and clusters differentiated by color. - Output:
The clustered results are saved in a CSV file, including each entity and its assigned cluster. Additionally, a scatter plot highlights the cluster structure, complete with example entities for each group.


K-Means clustering is highly effective for organizing large datasets into meaningful groups without requiring labeled data. By combining it with TF-IDF and PCA, we create a powerful pipeline for uncovering hidden relationships in textual data, which is invaluable for tasks like keyword research, topic modeling, and entity analysis.
Keyword to topic mapping with BERTopic
BERTopic is an advanced topic modeling library that combines the power of transformers and clustering to extract meaningful topics from text data. It excels in identifying semantic patterns and grouping related terms, making it an ideal tool for analyzing and organizing large keyword datasets.
Unlike traditional topic modeling methods, BERTopic uses embeddings generated from transformer models like Sentence-BERT, enabling it to capture nuanced semantic relationships. This makes it particularly effective for tasks like keyword clustering and topic discovery in content strategy and SEO.
How BERTopic Works for Keyword Analysis
- Input and Preparation:
The process starts with a CSV file (keywords.csv) containing a column of keywords to be analyzed. These keywords are loaded into a DataFrame for processing. - Embedding and Topic Discovery:
BERTopic generates embeddings for each keyword using a transformer-based model, capturing their semantic meanings. It then applies a clustering algorithm to group similar keywords into topics, assigning each keyword to the topic it aligns with most closely. - Topic Summarization:
Once the topics are formed, BERTopic provides a summary of each topic, including representative keywords. This offers a clear view of the thematic structure of the dataset. - Results and Outputs:
The results are saved in two CSV files:keywords_with_topics.csv: A file mapping each keyword to its assigned topic.topic_summary.csv: A summary of the discovered topics and their representative keywords.



What sets BERTopic apart is its ability to handle complex, unstructured data and produce interpretable results. By leveraging transformer embeddings and dynamic clustering, BERTopic generates topics that are both precise and meaningful, making it a game-changer for keyword analysis.
Click here to view a part of the Python Code for this section
import pandas as pd
from bertopic import BERTopic
# Step 1: Load the Keywords Data
# Replace this with file upload if you're in Colab
from google.colab import files
print("Please upload your keywords.csv file:")
uploaded = files.upload() # Prompts user to upload the file
keywords_file = list(uploaded.keys())[0] # Gets the uploaded file name
# Read keywords into a DataFrame
keywords_df = pd.read_csv(keywords_file)
keywords = keywords_df['Keywords'].tolist()
# Step 2: Initialize BERTopic
topic_model = BERTopic(verbose=True)
# Step 3: Fit BERTopic to the Keywords
topics, probs = topic_model.fit_transform(keywords)
# Step 4: Add Topics to DataFrame
keywords_df['Assigned Topic'] = topics
# Step 5: Get Topic Information
# Generate a summary of the topics and their associated keywords
topic_info = topic_model.get_topic_info()
topics_details = {topic: topic_model.get_topic(topic) for topic in topic_info['Topic'] if topic != -1} # Exclude outliers
# Save results
keywords_df.to_csv("keywords_with_topics.csv", index=False)
topic_info.to_csv("topic_summary.csv", index=False)
print("Topic extraction complete! Files saved as 'keywords_with_topics.csv' and 'topic_summary.csv'.")
# Download the output file
files.download("keywords_with_topics.csv")
files.download("topic_summary.csv")Key Takeaways on Mapping Keywords to Topics with Machine Learning
Mapping keywords to topics is more than just an exercise in data organization—it’s about understanding the deeper semantic relationships between terms and uncovering patterns that inform strategy. Over the years, I’ve seen how integrating machine learning approaches into this process can revolutionize how we think about keyword research and topic modeling. Let me share some of the key lessons and insights that have made a significant difference in my work with clients and teams.
A Framework for Structuring Insights
Machine learning methods provide the structure we need to make sense of massive keyword datasets. Each method brings its strengths to the table:
- String fuzzy matching is straightforward and effective for smaller-scale projects where speed and simplicity are key.
- K-Means Clustering allows you to group keywords into clear clusters when you have vectorized data and a specific number of topics in mind.
- BERTopic shines when exploring large, unstructured data, offering a dynamic way to identify emergent themes.
- sBERT provides precise, nuanced grouping for those moments when understanding the subtle contextual connections between terms is critical.
Together, these techniques form a toolkit that you can adapt depending on the complexity and scope of your project.
Using Machine Learning for Smarter Decisions
The beauty of these models lies in their ability to go beyond surface-level keyword analysis. By leveraging embeddings, clusters, and semantic similarity measures, machine learning helps us:
- Simplify complexity: Large, unstructured datasets become organized frameworks that are easier to interpret and act on.
- Spot hidden opportunities: Models like BERTopic and sBERT surface connections and themes that manual analysis often misses.
- Refine with precision: Even a lightweight approach like string fuzzy matching can add tremendous value in aligning smaller datasets with clear goals.
- Fast-track to topic models creation: Working with these APIs can make it easier to automate content briefs, as well as fast-track the creation of topic models as the next logical step in improving content sytems.
Why It Matters for You
When I teach or consult, I often emphasize that keyword to topic mapping isn’t just a technical exercise—it’s a strategic one. Choosing the right ML approach empowers you to better understand your data. It’s not about forcing the most complex model onto your data; it’s about choosing the method that gives you actionable insights without unnecessary complexity.
For instance, simpler approaches like fuzzy matching can be great, when you’re trying to map out entities contained in a term to the queries typed by users (i.e. you know a term is contained in the query), or matching queries to titles. More complex approaches, on the other hand are a better choice for deeper analyses to help uncover semantic relationships between the user queries in your keyword universe, and this can be a great way to fast-track subsequent content strategy steps.
Integrating machine learning into your keyword mapping workflow doesn’t just make the process more efficient; it makes it smarter, sharper, and deeply aligned with your goals. I’d encourage you to experiment, adapt, and find the balance that works for you and your data.
Author

AUTHOR
Lazarina Stoy.
DATE PUBLISHED
LAST MODIFIED
BUY A COURSE


More from the blog
-
Different ways to Map Keywords to topics – with Supervised and Unsupervised ML approaches

-
How to use Google Autocomplete API and Places API for Keyword Suggestions with Python

-
How to do keyword clustering with KeyBERT

-
How to use generative AI with structured data for programmatic SEO

-
How to Automatically Optimize your SEO Metadata with FuzzyWuzzy and OpenAI in Google Colab

Recommended Topics
- Audio Transcription (1)
- Content Creation (1)
- Content Moderation (1)
- Entity analysis (1)
- Keyword research (3)
- Onpage SEO (1)
- Sentiment Analysis (1)
- Syntax analysis (1)
- Text Classification (1)
Popular Tags
Beginner BERTopic FuzzyWuzzy Google Autocomplete API Google Cloud Natural Language API Google Colab (Python) Google Sheets (Apps Script) Intermediate KeyBERT kMeans OpenAI API sBERT Whisper API
Share this post on social media:
One response to “Different ways to Map Keywords to topics – with Supervised and Unsupervised ML approaches”
Thanks for the article.
It’s always interesting to run different versions of processing and compare the results.Small hint (because I learned it two weeks ago):
Since a couple of month fuzzywuzzy is thefuzz: https://github.com/seatgeek/thefuzz
Leave a Reply