
Prompt engineering is one of the hot topics these days, and it is constantly changing due to rapid changes in the guidelines, the underlying technologies’ capabilities, as well as our understanding of them.
It is mostly known as making many attempts, changing, rewriting a prompt, until you find one that works for the task at hand.
I would like to build on this and share a pattern of building prompt templates that can be used in bulk, for the creation of product descriptions, email marketing messages, and any other type of content.
The key enabler in this pattern is the availability of structured data for many items, and for a consistent set of attributes.
N.B. Structured data in this case is referred to data that exists in a database (regardless of platform), and is structured in an Entity – Attribute – Value (EAV) model. In the example below, the entity is the product, the attributes are the size, color and price, and the variables are the numbers in the cell.
import pandas as pd
products = pd.DataFrame({
'product': ['Product A', 'Product B', 'Product C'],
'size': [10, 12, 15],
'color': ['blue', 'green', 'red'],
'price': [150, 180, 125]
})
products| product | size | color | price |
|---|---|---|---|
| Product A | 10 | blue | 150 |
| Product B | 12 | green | 180 |
| Product C | 15 | red | 125 |
A very simple prompt for a product description for one of those products can be something like this:
Please create a product description for Product A Mention its size, which is 10 Also mention its color, which is blue And talk about its price: 150 The tone of voice should be professional
Now we have several important things to consider:
- Scalability – We would like to scale our prompting to encompass all our products.
- Consistency – The consistency of our data enables us to run the same process across many products.
- Reproducibility – It would be great if we can save the process that generated our product descriptions. This is in order to debug issues, reproduce them again, and eventually update them by tweaking the prompt or by adding new product attributes whenever we have updated data.
How to create prompts in bulk (a sample approach)
To continue the example, for our simple product dataset, we can create a simple for-loop that goes through the products and dynamically inserts the product’s attributes to the prompt:
prompt_template = """
Please create a product description for {product}.
Mention its size, which is {size}
Also mention its color, which is {color}
Talk about its price: {price}
The tone of voice should be professional
"""
for row in products.to_dict('records'):
print(prompt_template.format_map(row))
Please create a product description for Product A.
Mention its size, which is 10
Also mention its color, which is blue
Talk about its price: 150
The tone of voice should be professional
Please create a product description for Product B.
Mention its size, which is 12
Also mention its color, which is green
Talk about its price: 180
The tone of voice should be professional
Please create a product description for Product C.
Mention its size, which is 15
Also mention its color, which is red
Talk about its price: 125
The tone of voice should be professional
Let’s take a quick look at some of the advantages of this approach:
| Reproducibility | Eventually we will most likely want to update those descriptions. Obviously this is not a good prompt, doesn’t provide much context, and can be improved in many ways. We might have a new SEO strategy and want to focus on other aspects of our products. We might get new data, like user ratings for example, and might want to incorporate a new line in our prompt, and so on. |
| Scalability | This approach clearly allows us to create descriptions on a large scale, provided we have consistent data (n.b. think attributes and variables for each entity), and that the items are similar (belonging to the same product category, or are of the same type). |
| Debugging | If we see something wrong in our product descriptions, or some unwanted behavior, we can always go back and update our prompt template and clarify in a better way what we want. This enables us to start with any prompt, test for a few descriptions and keep iterating until we are satisfied. Then, we can run the prompt template across five thousand descriptions. |
| Minimizing hallucinations | Trusting LLMs to create product descriptions for you is risky business, because they are well-known for how easily they can invent “facts”, and also being “confident” about them. With this approach, we are restricting the factual information to the data that we provide, and we are also utilizing the great language processing capabilities of LLMs. We can also explicitly mention in the prompt something like, “only use the data provided.” |
Now that we have clarified the approach and its benefits, let’s see how this might be used in a real-life situation.
Project Overview
The example I will go through is for NBAstats.pro a website for NBA player statistics as the name suggests. It’s an experimental project for testing this approach and seeing how useful it can be for users, and how it might rank on search.
We will connect to the NBA data API, obtain career data for each player (per season and per metric), and use that to create profile pages for each player.
The main keyword template we are targeting here is “<player_name> stats”.
We will then build a prompt template that populates the player data dynamically into different prompts, and pass these on to an LLM – in this case, Open AI’s GPT.
The output will contain the prompt generated, the stats of the player that were passed on in the prompt, and the generated description that the LLM created for each of our players.
The Why – added value of using LLMs for product descriptions
Despite showing the process with a dummy dataset of NBA players, this approach is suitable for any programmatic SEO project with a well-structured database, and can be used for creating entire pages, if there is a robust template for each page. For e-commerce website, this approach can be a great way to scale and speed-up the writing process of product descriptions .
What we are doing here is not a simple re-arrangement of what someone else wrote and calling it our own. This would not add real value, and would not be an ethical thing to do. We are using publicly available data to uncover some insights, and with those facts creating an interesting description. This description should make the reader better informed about the topic discussed in two main ways:
Insights pulled to the surface from the raw data
With the availability of structured data about our players, we can make some calculations, and uncover some interesting facts that might not be immediately visible from the raw data.
For example, the raw data show how many points they scored every season, as well as how games they played. We can easily calculate the points per game and provide more insight than what the simple data might suggest. We can take this further by taking those totals or averages, and comparing them to all other players in the NBA, “Player A scored a total of X points in his career, putting him in the top Z players of all time.”
Charts and visualisations to aid data comprehension
Another added value we can add to the raw data is that we can visualize the data for truly more insightful perspectives into the players’ careers. We are targeting who are specifically searching for player stats, and they would most likely appreciate more insights into those stats through some visualizations.
How easy is it to understand Michael Jordan’s career stats by looking at this table?

Maybe this is better:
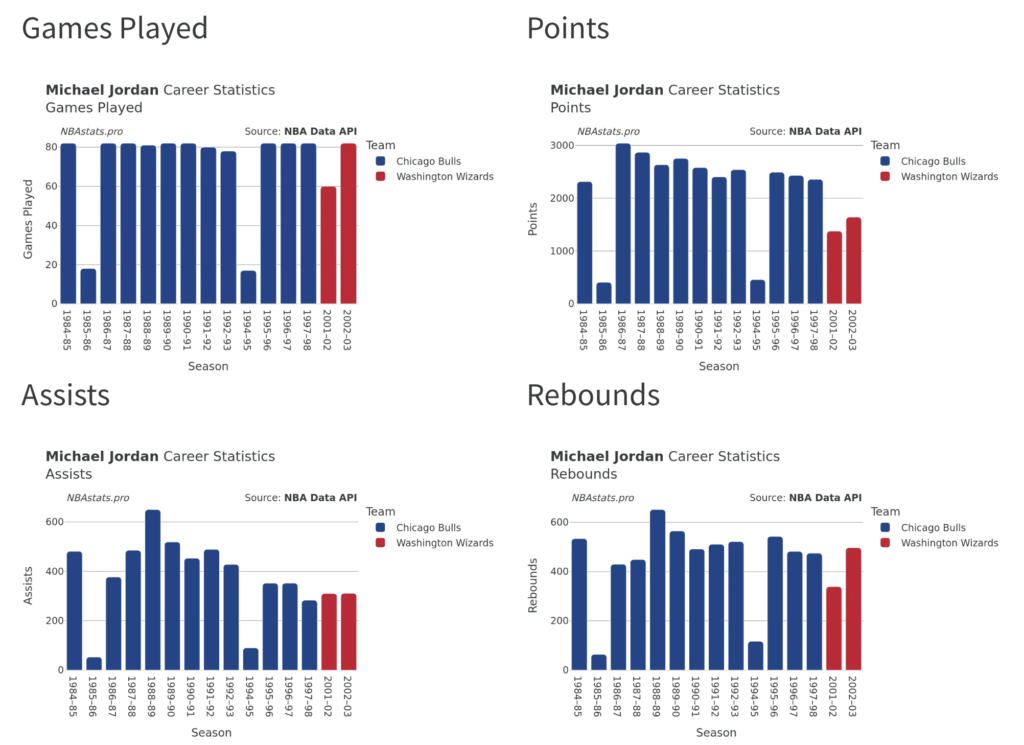
Was it easy for you to spot the two seasons where he played a very low number of games, and that otherwise he played pretty much all games of all seasons?
Was it clear from the table, that after his third year, his total points per season kept going down throughout his career (even though the games he played was stable, with two exceptions)?
Of course those charts are not produced by the LLM. We will produce them with Plotly, a Python data visualisation library, and of course we can use other libraries for that.
From an SEO perspective, we are also producing a lot of image assets which might hopefully also rank on image search for related terms. In this website, we have 8 charts per player, which is almost forty thousand charts in total. This is real content based on actual data, and we are using it to provide additional insights to our users.
How to use LLMs to create descriptions programmatically: Step-by-Step Guide
Just like what we did with the toy example above, we will now create a prompt template for NBA players.
Import libraries
import pandas as pd
from openai import OpenAI
from nba_api.stats.endpoints import playercareerstats
from nba_api.stats.static import players, teams
import plotly.express as px
pd.options.display.max_columns = None
import os
from IPython.display import display_markdown
def md(text):
return display_markdown(text, raw=True)
client = OpenAI(api_key=os.environ['OPENAI_API_KEY'])Get static data about players and teams (ID’s, full name, city, state, etc.)
These are two fairly stable datasets containing simple high-level data on players and teams.
players_static = players.get_players()pd.DataFrame(players_static).to_csv('players_static.csv', index=False)teams_static = teams.get_teams()pd.DataFrame(teams_static).to_csv('teams_static.csv', index=False)players_static = pd.read_csv('players_static.csv')
teams_static = pd.read_csv('teams_static.csv')players_static.sample(10)| id | full_name | first_name | last_name | is_active | |
|---|---|---|---|---|---|
| 3393 | 77825 | George Pearcy | George | Pearcy | False |
| 1849 | 1538 | Cedric Henderson | Cedric | Henderson | False |
| 4077 | 22 | Rik Smits | Rik | Smits | False |
| 2829 | 77517 | Paul McCracken | Paul | McCracken | False |
| 3022 | 600006 | Earl Monroe | Earl | Monroe | False |
| 4324 | 78340 | Mel Thurston | Mel | Thurston | False |
| 3460 | 2565 | Zoran Planinic | Zoran | Planinic | False |
| 1782 | 203914 | Gary Harris | Gary | Harris | True |
| 42 | 203128 | Furkan Aldemir | Furkan | Aldemir | False |
| 1094 | 76577 | Terry Dischinger | Terry | Dischinger | False |
teams_static.sample(10)| id | full_name | abbreviation | nickname | city | state | year_founded | |
|---|---|---|---|---|---|---|---|
| 13 | 1610612750 | Minnesota Timberwolves | MIN | Timberwolves | Minnesota | Minnesota | 1989 |
| 15 | 1610612752 | New York Knicks | NYK | Knicks | New York | New York | 1946 |
| 27 | 1610612764 | Washington Wizards | WAS | Wizards | Washington | District of Columbia | 1961 |
| 21 | 1610612758 | Sacramento Kings | SAC | Kings | Sacramento | California | 1948 |
| 6 | 1610612743 | Denver Nuggets | DEN | Nuggets | Denver | Colorado | 1976 |
| 9 | 1610612746 | Los Angeles Clippers | LAC | Clippers | Los Angeles | California | 1970 |
| 19 | 1610612756 | Phoenix Suns | PHX | Suns | Phoenix | Arizona | 1968 |
| 14 | 1610612751 | Brooklyn Nets | BKN | Nets | Brooklyn | New York | 1976 |
| 3 | 1610612740 | New Orleans Pelicans | NOP | Pelicans | New Orleans | Louisiana | 2002 |
| 1 | 1610612738 | Boston Celtics | BOS | Celtics | Boston | Massachusetts | 1946 |
players_static[players_static['full_name'].isin(['LeBron James', 'Michael Jordan'])]| id | full_name | first_name | last_name | is_active | |
|---|---|---|---|---|---|
| 2111 | 2544 | LeBron James | LeBron | James | True |
| 2291 | 893 | Michael Jordan | Michael | Jordan | False |
Get player career stats using the player’s ID
The playercareerstats endpoint is responsible for providing all the data for each player. For this we need the player’s ID which we can get from the previously obtained players_static table.
lebron_james = playercareerstats.PlayerCareerStats(player_id=2544)
michael_jordan = playercareerstats.PlayerCareerStats(player_id=893)lebron_james.get_data_frames()[0].head()| PLAYER_ID | SEASON_ID | LEAGUE_ID | TEAM_ID | TEAM_ABBREVIATION | PLAYER_AGE | GP | GS | MIN | FGM | FGA | FG_PCT | FG3M | FG3A | FG3_PCT | FTM | FTA | FT_PCT | OREB | DREB | REB | AST | STL | BLK | TOV | PF | PTS | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2544 | 2003-04 | 00 | 1610612739 | CLE | 19.0 | 79 | 79 | 3120.0 | 622 | 1492 | 0.417 | 63 | 217 | 0.290 | 347 | 460 | 0.754 | 99 | 333 | 432 | 465 | 130 | 58 | 273 | 149 | 1654 |
| 1 | 2544 | 2004-05 | 00 | 1610612739 | CLE | 20.0 | 80 | 80 | 3388.0 | 795 | 1684 | 0.472 | 108 | 308 | 0.351 | 477 | 636 | 0.750 | 111 | 477 | 588 | 577 | 177 | 52 | 262 | 146 | 2175 |
| 2 | 2544 | 2005-06 | 00 | 1610612739 | CLE | 21.0 | 79 | 79 | 3361.0 | 875 | 1823 | 0.480 | 127 | 379 | 0.335 | 601 | 814 | 0.738 | 75 | 481 | 556 | 521 | 123 | 66 | 260 | 181 | 2478 |
| 3 | 2544 | 2006-07 | 00 | 1610612739 | CLE | 22.0 | 78 | 78 | 3190.0 | 772 | 1621 | 0.476 | 99 | 310 | 0.319 | 489 | 701 | 0.698 | 83 | 443 | 526 | 470 | 125 | 55 | 250 | 171 | 2132 |
| 4 | 2544 | 2007-08 | 00 | 1610612739 | CLE | 23.0 | 75 | 74 | 3027.0 | 794 | 1642 | 0.484 | 113 | 359 | 0.315 | 549 | 771 | 0.712 | 133 | 459 | 592 | 539 | 138 | 81 | 255 | 165 | 2250 |
michael_jordan.get_data_frames()[0].head()| PLAYER_ID | SEASON_ID | LEAGUE_ID | TEAM_ID | TEAM_ABBREVIATION | PLAYER_AGE | GP | GS | MIN | FGM | FGA | FG_PCT | FG3M | FG3A | FG3_PCT | FTM | FTA | FT_PCT | OREB | DREB | REB | AST | STL | BLK | TOV | PF | PTS | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 893 | 1984-85 | 00 | 1610612741 | CHI | 22.0 | 82 | 82 | 3144.0 | 837 | 1625 | 0.515 | 9 | 52 | 0.173 | 630 | 746 | 0.845 | 167 | 367 | 534 | 481 | 196 | 69 | 291 | 285 | 2313 |
| 1 | 893 | 1985-86 | 00 | 1610612741 | CHI | 23.0 | 18 | 7 | 451.0 | 150 | 328 | 0.457 | 3 | 18 | 0.167 | 105 | 125 | 0.840 | 23 | 41 | 64 | 53 | 37 | 21 | 45 | 46 | 408 |
| 2 | 893 | 1986-87 | 00 | 1610612741 | CHI | 24.0 | 82 | 82 | 3281.0 | 1098 | 2279 | 0.482 | 12 | 66 | 0.182 | 833 | 972 | 0.857 | 166 | 264 | 430 | 377 | 236 | 125 | 272 | 237 | 3041 |
| 3 | 893 | 1987-88 | 00 | 1610612741 | CHI | 25.0 | 82 | 82 | 3311.0 | 1069 | 1998 | 0.535 | 7 | 53 | 0.132 | 723 | 860 | 0.841 | 139 | 310 | 449 | 485 | 259 | 131 | 252 | 270 | 2868 |
| 4 | 893 | 1988-89 | 00 | 1610612741 | CHI | 26.0 | 81 | 81 | 3255.0 | 966 | 1795 | 0.538 | 27 | 98 | 0.276 | 674 | 793 | 0.850 | 149 | 503 | 652 | 650 | 234 | 65 | 290 | 247 | 2633 |
Create a prompt template and dynamically insert each player’s data
Just like we did with the simple prompt template above, we can do the exact same thing we did above. Note that since we have more data and of different types, the loop is not as straightforward.
For example, for most columns we get the sum of the column to get the player’s career stats for that metric (games played, steals, blocks, etc.). In some cases, like seasons played, and teams played for, it doesn’t make sense to sum these values.
responses = []
for player_id in [2544, 893, 203999, 76003]:
player_stats_df = playercareerstats.PlayerCareerStats(player_id=player_id).get_data_frames()[0]
player_stats_df = pd.merge(
player_stats_df,
players_static,
left_on='PLAYER_ID',
right_on='id',
how='left')
player_stats_df = pd.merge(
player_stats_df,
teams_static,
left_on='TEAM_ID',
right_on='id',
how='left')
display(player_stats_df)
# player_id = int(player_id.replace('player_', '').replace('.csv', ''))
# t0 = time.time()
try:
df = player_stats_df[player_stats_df['PLAYER_ID'].eq(player_id)]
if (df['FGM'].sum() > 0) and (df['FGA'].sum() > 0):
goals_percent = df['FGM'].sum() / df['FGA'].sum()
else:
goals_percent = 'unknown'
if (df['FTM'].sum() > 0) and (df['FTA'].sum() > 0):
freethrows_percent = df['FTM'].sum() / df['FTA'].sum() > 0
else:
freethrows_percent = 'unknown'
d = dict(
name = df['full_name_x'].iloc[0],
teams = df['full_name_y'].drop_duplicates().dropna().tolist(),
cities = df['city'].drop_duplicates().dropna().tolist(),
states = df['state'].drop_duplicates().dropna().tolist(),
active = df['is_active'].iloc[-1],
start_season = df['SEASON_ID'].iloc[0],
end_season = df['SEASON_ID'].iloc[-1],
start_age = df['PLAYER_AGE'].iloc[0],
end_age = df['PLAYER_AGE'].iloc[-1],
games_played = df['GP'].sum(),
minutes_played = df['MIN'].sum(),
goals_attempted = df['FGA'].sum(),
goals_made = df['FGM'].sum(),
goals_percent = goals_percent,
freethrows_attempted = df['FTA'].sum(),
freethrows_made = df['FTM'].sum(),
freethrows_percent = freethrows_percent,
rebounds = df['REB'].sum(),
rebounds_def = df['DREB'].sum(),
rebounds_off = df['OREB'].sum(),
assists = df['AST'].sum(),
steals = df['STL'].sum(),
blocks = df['BLK'].sum(),
points = df['PTS'].sum(),
)
prompt = [
{"role": "system",
"content": """
You are a smart, detail-oriencted, keen NBA Basketball player analyst.
Please write an introductory text for a profile page of this Basketball player.
Length: 500 - 800 words.
please stick to the stats provided.
Tone: should be interesting factual intriguing and inviting the user to dive
into the charts on the page to better get to know the player."""},
{"role": "user",
"content": f"""
Please write and article for the player using the following details:
{d}"""}]
display(md(f"## {df['full_name_x'].iloc[0]}"))
for k, v in prompt[0].items():
print(k, v)
print()
for k, v in d.items():
print(k, v)
except Exception as e:
print(str(e))
continue
completion = client.chat.completions.create(
# model="gpt-4o",
model="gpt-3.5-turbo",
messages=[
{"role": "system",
"content": """You are a smart, detail-oriencted, keen NBA Basketball player analyst. \
Please write an introductory text for a profile page of this Basketball player.
Length: 500 - 800 words.
please stick to the stats provided.
Tone: should be interesting factual intriguing and inviting the user to dive \
into the charts on the page to better get to know the player.
"""},
{"role": "user",
"content": f"""Please write and article for the player using the following details:
{d}
"""}
]
)
responses.append([player_id, completion])
print()
print(completion.dict()['choices'][0]['message']['content'])
print()
display(md('----'))The system response would look like this – first summarising the generated prompt, then the player stats, then followed by the generated text. The below is an example for the player Nikola Jokic.
role system
content
You are a smart, detail-oriencted, keen NBA Basketball player analyst.
Please write an introductory text for a profile page of this Basketball player.
Length: 500 - 800 words.
please stick to the stats provided.
Tone: should be interesting factual intriguing and inviting the user to dive
into the charts on the page to better get to know the player.
name Nikola Jokic
teams ['Denver Nuggets']
cities ['Denver']
states ['Colorado']
active True
start_season 2015-16
end_season 2023-24
start_age 21.0
end_age 29.0
games_played 675
minutes_played 21077.0
goals_attempted 9778
goals_made 5450
goals_percent 0.5573736960523624
freethrows_attempted 3099
freethrows_made 2563
freethrows_percent True
rebounds 7249
rebounds_def 5466
rebounds_off 1783
assists 4667
steals 822
blocks 491
points 14139
Nikola Jokic: The Game-Changing Force from the Mile High City
When it comes to the realm of basketball, few players possess the unique blend of skills and basketball IQ that Nikola Jokic brings to the court. As a key player for the Denver Nuggets since the 2015-2016 season, Jokic has not only solidified his place as one of the league's top players but has also become a fan favorite in the city of Denver, Colorado.
Standing at 7 feet tall, Jokic cuts an imposing figure on the court, but it's his finesse and versatility that truly set him apart from his peers. With a stellar field goal percentage of 55.7%, Jokic has proven time and time again that he has the scoring touch to make an impact in any game situation. His ability to stretch the floor as a center, with a reliable mid-range shot and three-point range, makes him a nightmare matchup for opposing defenders.
But Jokic's impact goes beyond just scoring. His passing ability and court vision are arguably what truly elevate his game to the next level. With an impressive 4667 assists over his career, Jokic is not just a scorer - he is a playmaker, constantly creating opportunities for his teammates and keeping the Nuggets' offense flowing smoothly.
On the defensive end, Jokic is equally impactful. With 7249 total rebounds, including an impressive 1783 offensive rebounds, Jokic is a force on the boards, giving his team crucial second-chance opportunities and limiting opponents' offensive possessions. His 822 steals and 491 blocks also showcase his ability to disrupt plays and protect the rim when called upon.
As a truly all-around player, Jokic's impact on the court cannot be overstated. His versatility, basketball IQ, and unique skill set make him a player that opposing teams must always account for and game-plan against. It's no wonder that he has become the face of the Denver Nuggets and a player that fans in the Mile High City have come to adore.
Through 675 games played and over 21,000 minutes on the court, Jokic has consistently proven himself as a reliable and game-changing presence for the Nuggets. His numbers speak for themselves - with 14139 points scored and counting, Jokic continues to be a dominant offensive force for his team.
At just 29 years old, Jokic is still in the prime of his career, with plenty of basketball ahead of him. As he continues to evolve and refine his game, there's no telling how far he can take the Nuggets and what accolades he can achieve in the years to come.
For fans of the game looking to witness a player who truly embodies the essence of modern basketball - a player who can score, pass, rebound, and defend with equal prowess - look no further than Nikola Jokic. Dive into the stats, dissect his game, and marvel at the skill and talent of this basketball virtuoso from Denver.
Review the generated texts
Now let’s review the generated text for some of the key players:
LeBron James

Michael Jordan

Summary
This was a quick overview of how we can use LLMs to create content in bulk. The sole requirements being having clean, correct, and consistent data, in a structured format.
This enables us to scale the content creation process to make articles or product descriptions.
The fact that we have the full process of creating the descriptions empowers us even more because we can always recreate the content if and when the data changes, as will definitely happen with NBA stats, or if we want to change the tone of voice, focus of the article, or change any aspect of it.

Elias Dabbas
Elias is a digital marketing and Data Science practitioner. He is the creator and maintainer of the Python library advertools, and is the author of the book Interactive Dashboards and Data Apps with Plotly and Dash. He was motivated to start learning and implementing ML in Organic Search by the possibilities of discovering trends, insights, as well as improving his overall productivity. Some of his most successful MLforSEO projects include: fine-tuning a model that extracts entities from articles and gets their Wikipedia URLs, which was later also implemented as an interactive app. Some notable work Elias has done in ML/SEO includes nbastats.pro project and the adver.tools suite of ML technologies.
- Elias Dabbas




